训练集群最昂贵的浪费之一,是 GPU 已经就位,数据却还在路上。数据集越来越大,模型发布节奏又从数月压缩到数周,存储容量、传输速度和计算供给之间的落差随之放大。Meta 此次公开的扩容蓝图,目标很直接:提高 GPU 利用率,同时缩短研究人员搬运和准备数据的时间。需要说明的是,本文信息全部来自 Meta 官方工程博客,缺少独立信源交叉验证。
一套底座,三种入口
Meta 表示,公司运营数百个 exabyte-scale 存储集群,服务 Facebook、Instagram、Reality Labs、Meta AI、Ads、Data Warehouse 和内部数据库。这里的原文可能指单个集群达到 EB 级,也可能描述整个集群体系的规模,不能直接理解为“数百 EB 数据”。
这些系统对外提供对象存储、文件系统和块设备 API,但底层都落在 Tectonic 上。Tectonic 是一个区域级、多租户的横向扩展块存储层。它用纠删码提高持久性和可用性,并支持 HDD、flash 等介质的分层存储——按速度、容量和成本分配数据,再根据冷热程度调整位置。
Meta 曾在 Tectonic 上提供类似 NFS 的文件系统接口,直接用它训练 Llama。如今,现代训练栈正逐步迁移到 BLOB-storage 接口,希望统一访问大规模数据湖,并获得更高性能。旧接口仍在 Meta 内部广泛使用,因此这不是一次彻底切换。
GPU 为什么会等存储
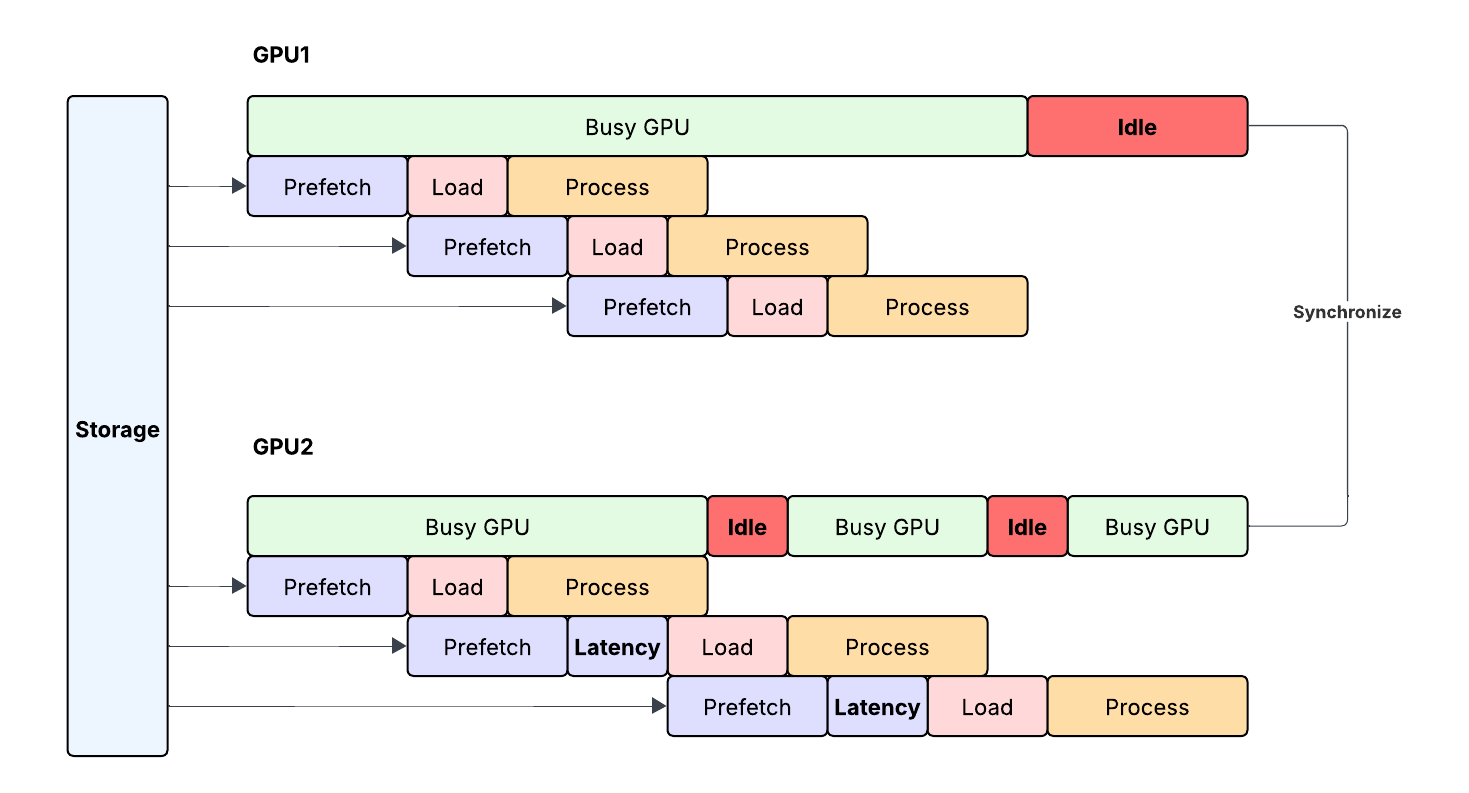
存储吞吐量决定单位时间能搬多少数据,I/O 延迟则是一次请求要等多久。大规模训练会反复读取数据,并按批次推进;GPU 还会周期性同步状态。只要一块 GPU 因读取变慢而掉队,整个同步步骤都可能被拖住。
预取可以把下一批数据提前送到 GPU 主机,让计算与 I/O 重叠。但它只能隐藏正常范围内的延迟,挡不住长尾。Meta 因此强调 pMax 延迟,也就是最慢一端的请求表现,而不只是平均吞吐。
问题在于,旧 BLOB-storage 架构多年叠加了多个有状态服务层,每层又维护自己的元数据。一次 getObject 请求需要依次查询 name、volume 和 container 等层级,才能把路径解析成底层块位置。部分查询还会跨区域。Meta 称,这些延迟可能累计到数百毫秒;对以毫秒速度访问 flash 的 AI 工作负载而言,任一慢查询都足以形成阻塞。
值得关注的不只是容量
Meta 给出的判断是:AI 计算性能约每两年增至三倍,而存储与互连——连接计算、存储和网络设施的数据通道——增长较慢,存储瓶颈因此成为 GPU 停顿的主要原因之一。与此同时,GPU 日益跨地域分布,研究人员也要花更多时间摄取和跨区域移动海量数据。
这份蓝图真正指出的是,AI 存储不能只追求“装得下”。吞吐、长尾延迟、数据位置和访问接口会共同决定昂贵计算资源是否持续工作,也会影响一次实验从准备到运行需要多久。
局限与未知
- Meta 未披露容量、吞吐、延迟、GPU 利用率、故障率或成本改善数据,所谓“高性能”“高可用性”等仍是官方概括。
- “计算性能约两年增至三倍”和“模型发布间隔缩至数周”均未说明统计口径与样本。
- 供稿未完整展开新架构如何消除多层元数据查询、控制长尾延迟,以及迁移的具体进度。